- Ctrl + 矢印キー
-
データの端までジャンプ
- Shift + 矢印キー
-
データエリアの選択
- Ctrl + Shift + 矢印キー
-
データエリアの端まで一気に選択
- マウスの右ボタン(コンテクスト・メニュー)
-
Excelに限らず、
MS系のソフトウェアでは色々な機能が割り当てられていることが多い。
コピー、(形式を指定して)貼付け、セルの書式設定あたりが、
おそらく一番利用頻度が高いと思う。
- ショートカット
-
マウスの右ボタンで操作すると、意外とミスがおきやすいので、
次のようなショートカットを覚えておくとよいかもしれない。
Ctrl+C で “コピー”、
Ctrl+V で “貼り付け(ペースト)”、
Ctrl+X で “切り取り(カット)”
- 日本語入力は原則的に常にOFF
-
関数などを利用するとき、アドレスなどを入力するとき、
基本的にIM(変換ソフト)はOFFにしないとエラーが起きる。
関数の入力支援ウィザードを使う場合は別として、
セルの編集ウィンドウに直接入力する場合には、
半角文字以外は原則的に受け付けない(くらいに…)と考えた方が安全。
特に、文字列であることを指定するときにダブルコーテーションマーク(”)を使ったり、
引数のセパレーターにカンマ(,)を使うが、
これらが全角文字だとエラーになるので要注意。
ちなみに、全角文字のカンマは,で、
半角文字のカンマは,である。比べてみてほしい。
- 分割表示
-
Excelのヴァージョンによって分割させる手続きが変わりますが基本的な機能は同じ。
分割表示をすることで入力ミスなどが防げる。
特に先頭行と他の行を区別して表示する形式を強く推奨します。
- 四則演算
-
それぞれ、+、ー、*、/を使う。べき乗は^を利用する。例えば、2^3 は8となる。
この場合も、必ず関数であることを宣言して使う。例えば、=A1+B1-C1。必ず=を付けること。
括弧()で演算順序を指定することができる。
*と/は+やーよりも先に実行されるが、
凡ミスを防ぐためにも、
括弧を使って明示的に演算順序を表現すべきである
(e.g., = 5 + 4 /2 ≠ = (5 + 4) /2)。
- Excelの関数
-
一般的には=()のような形式をとる。
たとえば,=average()で平均値を求めることができるが,括弧のなかに範囲(B2:B101)を指定する。
更に=COUNTIF(範囲, 検索条件)のような関数では条件を満たすデータ入力されているセルを検索し,その個数を求めることができる。
たとえば,=COUNTIF(C2:C101, "上位群")は範囲(C2:C101)のなかで上位群と示されいるセルが幾つあるのかカウントできる。ちなにみ,数字以外の文字列を引数とする場合は必ずダブルクオーテーションマーク(”)で括る必要がある。
- 平均,合計,個数の確認は関数不要
-
平均や合計を確認するだけならば,
求めたいデータの範囲を選択することで当該範囲の平均,合計,個数が
下のステータスバーに示される。
少し応用的な使い方であるが,
Ctrlキーを押しながら選択していっても同様の数値が表示される。
また同様の理屈であるが,並べ替えをしたうえで区間を選択すると,
並べ替えられた特定の条件に合致した区間の平均,合計が求められるようになる。
もちろん平均(average)や合計(sum),daverage
といった関数も利用可能である。
必要に応じて使い分けるべきである。
- セルに表示される様々なエラーメッセージ
-
Excelでは表示できない式の結果が出たときなどに
エラー値という形で色々な警告が表示されます。
以下に主なものを挙げてみました。
- ### → セルの幅よりも長い数値になってしまったときに表示される。
適正なセル幅に調節すると問題が解決する。
- #VALUE! →
関数・数式に使う引数の種類が間違っていた。数式を正しく入れ直すことで解決する。
- #DIV/0! → 0(ゼロ)で割り算が行われたときに表示される。
- #REF! → セルの削除などでセルの参照が無効になってしまった結果生じるエラー。
参照している箇所をチェックして正しくする。
- 8.88888E-05のような指数表示になった場合は、セルの表示の桁数を増やせば0.0000888888のように表示される。
一般的には統計学的な分析を行っているときに強い有意差が得られたときに遭遇するが、驚かないで「統計学的に有意な値が得られた」と解釈してスルーしてかまわない。
- エラーが生じたときの回避策
-
データ数が100個といった具合に少なければ問題ありませんが、それが500個とか多くなると計算エラーが発生すると憂鬱になります。
エラー値として有名なものとしては、上述した#DIV/0!(divided by zero)などがあります。
例えば、ある尺度の平均値を求めたい場合に、特定の被験者の回答がその部分だけ無回答ということはよくあることです。
そのような場合に、その被験者の回答を全て削除してもかまいませんが、しかし、数年間にわたる経年変化を見たいような場合だと全て削除してしまうのは勿体ないです。
このような微妙な状況において有効な関数として、下記で詳述するようなIF文とISERROR関数があります。
具体的には、=IF(ISERROR(AVERAGE(X3:AA3)), "", AVERAGE(X3:AA3)) のように使うと、#DIV/0!のようなエラーが出たら””(空白)を返し、そうでなければ普通に平均値を計算することになります。
データが大量にあるときには便利なTIPSでしょう。
いちいち、IF(ISERROR…を使って平均値や標準偏差を計算するのは大変かもしれませんが,大量のデータを扱う場合には必須の工夫といえます。
※ =IFERROR(AVERAGE(N2:S2),"")とすると
平均値の関数 AVERAGE(N2:S2) の値がない場合は
空欄””が返されます。
しかし,Excel上では””は空欄ではなく””として認識されるためトラブルが生じることがあります。
そのような場合には以下のような工夫をすることで回避できます。
=IF(T2="","", IF(T2>(T$1070+0.5*T$1071), "Upper", IF(T2<(T$1070-0.5*T$1071),"Lower", "Middle")))
つまり,T2の中に””があれば,””を返し,
そうでなければIF文で分岐判断を行うわけです。
蛇足ながら,この例では,
T2がT$1070+0.5*T$1071よりも多ければUpperと返し,
T2がT$1070-0.5*T$1071よりも少なければLowerと返し,
そうでなければMiddleとなる条件式となっています。
- 入力した数字が文字列として認識される
-
色々な要因で入力した数字が文字列(計算の対象とならない)となってしまうことがあります。
まさにマイクロソフトマジックですが,その場合は「データ」メニューから「区切り位置」を変更すると文字列から数字に修正されます。
なぜその様な仕様になっているかは不明ですが,文字列になってしまったセルを数字に変更する有効なTIPSといえます。(Excel 2016)
- アドレスの相対指定
-
関数などをコピーして別のセルに貼付けると、
その中のデータ領域(引数)のアドレスが平行移動する
- アドレスの絶対指定(参照)
-
関数をコピー・貼付けを行う時に、
特定の値を常に参照したいことがある(たとえば、データの標準化をするときには、常に同じ標準偏差を分母に使う)。
この場合、アドレスの相対指定では同じ値を参照し続けることができないので、
絶対指定をする必要がある。
アドレスの絶対指定は、行(数字で表示)や列(アルファベットで表示)の直前にドルマーク“$”をつける。
たとえば、上述した標準化の場合は行のアドレスを固定する必要があるが、
このようなときにはZ$11とすればよい。
列のアドレスを固定したいときには$Z11といった具合いに指定する。
行・列ともに絶対指定したい場合には、$Z$11とかく。
アドレスの編集は、
数式編集エリアにマウスのカーソルを移動して半角文字で入力するか、
カーソルを移した状態でF4を(何回か)押す。
セルの指定の仕方は以下のように4種類存在する。
例文: =IF ( K2> K85, ”Large” , ”Small”)
【K2がK85の値よりも大きければ、Largeと表示せよ、そうでなければSmallと表示せよ】
- 相対指定: (例)K85 ←上記の関数などをコピーペーストすると、セルの番地が相対的に変化する。
それを防ぐために、以下のような絶対指定を行う。
- 行と列ともに絶対指定: (例)$K$85
- 列だけ絶対指定: (例)$K85
- 行だけ絶対指定: (例)K$85
ちなみに,尺度内の各質問項目の相関行列を作るときに、アドレスの絶対指定をどのように組み合わせればよいだろうか?
- 条件つき書式
-
たとえば、相関行列などを計算したときに、0.4以上の値は黄色、0.5以上は黄緑、0.6以上は水色といった具合に色づけをすると、項目間の関係がビジュアルに分かりやすくなる(もっとよい配色があるはずですが…)。メニューの中の「書式(o)」をクリックすると、「条件付き書式」があらわれるので、あとは条件を投入すれば完了。
(Exel2010では,リボン式のインターフェースに則って,
ホームのメニューの中にある条件式書式を選んで指定します)
- 変数は第一行目に全て書く
-
変数名が空欄のままだと、
ピボットテーブルや条件つき平均などを求めるときにエラーがおきたりする。
面倒でも、必ず、初めの行には変数を入れておくべき。
また、後から読んでも分かるように、変数名はなるべく説明的に設定すべきだと思う。
この場合の「後から」というのは、一週間後とかではなくて、
半年後、一年後という意味である。
必要ならば、セルに対してコメント(作業メモ)もつけておくとよいと思う。
- 形式を選択して貼り付け
-
質問紙などを作成していると、凝った書式のセルが必要になったりします。
初めに全てのセルのレイアウトが確定していればいいのですが、
たいていは特定のセルの書式を試行錯誤しながら確定していくと思います。
既に質問項目がセルの中に入っていたりすると、
単純にコピー・ペーストしてしまうとせっかくの文章が上書きされてしまいます。
「書式」に関する情報だけをコピーして他のセルに
ペーストしたいようなこともあるのが分かると思います。
そのような場面で重宝する操作が、「形式を選択して貼り付け」です。
まず始めに、「書式をコピーしたいセル」にカーソルを合わせて「コピー」します。
この操作は通常のコピペと全く同じものです。
次に、その書式の情報を貼り付けたいセルにカーソルを合わせ、その状態でマウスの右ボタンをクリックします。
そうすると、コンテクストメニューがポップアップしてくるので、
その中から「形式を選択して貼り付け」を選び、「書式」を選択し「OK」ボタンを押します。
「形式を選択して貼り付け」の中には「行列を入れ替える」といった
オプションがあったりするので、
書式をコピー・ペーストする以外にも色々な使い道があります。
- ドロップダウンリスト(別名プルダウンリスト?)によるデータ入力
-
数値データだけ入力しているときには関係ない話ですが、
文字列、特に日本語を入力するときに面倒なことがあります。
一々IMモードに切り替えて入力しなければならないからです。
また、Excelで文字を入力すると、過去に入力された文字列が自動的に補完されることがありますが、
必ずしも意図した文字列ではないかもしれません。
このようなときに便利な仕組みがドロップダウンリストです。
- メニュー[データ]→[入力規則]をクリック
- [データの入力規則]ダイアログ→[設定]タブをクリック
- [条件の設定]欄の[入力値の種類]コンボボックスから「リスト」を選択
このとき注意すべきことは、「元の値」のところで
「, 」半角カンマ+半角スペースでつなぐということです。
例えば、このように半角カンマと半角スペースで区切るわけです。
【 幼児教育コース, 子ども文化コース, 教育学コース,
教育心理学コース, 国語教育コース … 】
このように長い名前を正確にエラーせずに入力することは不可能でしょう。
ドロップダウンリストを使うようにして下さい。
- オートコンプリートを解除するには?
-
便利な機能ではありますが使わないときにはかえって邪魔になります。
そのようなときにはオートコンプリートを解除しましょう。
メニューバーの【ツール】→【オプション】表示される
ダイアログボックスの【編集】タブにある
【オートコンプリートを使用する】のチェックを外します。
以下は関数の中でも使用頻度が高そうなもののリストである。
見易くするために空白を適宜入れているので、
そのまま貼付けてもうまく行かないのでご注意を。
また、括弧の中の「領域」は引数とよばれる変数である。
引数を複数個指定する関数もあり、その場合には、各々の引数はカンマで区切る。
- = sum ( 領域 )
-
指定したデータ領域の合計値を計算する。
ちなみに、SUMはスムではなくて、サムと読んでほしい(summationなので)。
ALTキーもその手の怪しいローマ字読みがされやすいが…。
類似の関数に、dsumとsumifがある。
複数の条件に合致する合計を出力してくれる。
DSUMは、=DSUM(データ領域, 合計を求めるデータ項目名, 条件が入力されている領域)である。
たとえば、=dsum(A1:D100, "教科", D105:F105)といった感じに使う。
条件となる項目名(ここでは教科)は、必ず、
基となるデータ領域の項目名と同じでなければならない。
ただし、daverageと同様に、変数が入っているアドレスを指定してもかまわない。
以下、dstdevでも同じ。
- = average ( 領域 )
-
指定したデータ領域の平均値を計算する。
類似の関数に、daverageがある。
複数の条件に合致する平均を出力してくれる。
DAVERAGEは、=DAVERAGE(データ領域, 合計を求めるデータ項目のアドレス, 条件が入力されている領域)である。
たとえば、=daverage(A1:E1463, E1, G1466:H1467)といった感じに使う。
グラフを作成するときに、並べ替えをする方法もあるけど、こちらの方が圧倒的に楽チン。

男子(SEXが1)で課外活動をしている児童(CLUBが1)の一ヶ月の読書数の平均を計算している
- =averageif(領域,条件,平均対象領域)
- = median ( 領域 )
-
指定したデータ領域の中央値を計算する。
- = mode ( 領域 )
-
指定したデータ領域の中央値の最頻値を計算する。
- = stdev ( 領域 )
-
指定したデータの標準偏差を調べる。
得られたデータが母集団全体であれば、stdev.pを使う。例えば全数調査,悉皆調査と呼ばれている調査であれば得られる標準偏差は母集団の標準偏差である。
通常の心理学調査の場合は、サンプリングされていることを仮定しているので,標本標準偏差stdev.sを使うことになる。
STDEVは、STandard DEViationの略。
類似の関数に、dstdevがある。
複数の条件に合致する標準偏差を出力してくれる。
DSTDEVは、=DSTDEV(データ領域, 合計を求めるデータ項目のアドレス, 条件が入力されている領域)である。
たとえば、=dstdev(A1:D100, E1, D105:F105)といった感じに使う。
余談ですが上記の標準偏差(STDEV=σ)を利用して以下のように偏差値(Zi)を計算できます。
\[ Z_i= \frac{x_i - \overline{x} }{σ} + 50 \]
偏差【平均値−平均値】も標準偏差も同じ次元(単位)なので、
偏差値は特定の単位に依存しない比率の値となってます。
- = QUARTILE(領域,オプション)
-
四分位数を求める関数です。
オプションを指定することによって,0が最小値,1が第1四分位点,
2が第2四分位点,3が第3四分位点,4が最大値を返します。
第1四分位点とは下から0%〜25%と25%〜50%の区切りの値,
第2四分位点とは25%〜50%と50%〜75%の区切りの値,
第3四分位点とは50%〜75%と75%〜100%の区切りの値
と定義されます。
ちなみに,最小値を求める関数は=MIN(領域),最大値を求める関数は=MAX(領域)となっています。
- = TRIMMEAN(範囲,外れ値としてのパーセンテージ)
-
= TRIMMEAN(b2:b200, 0.16)のように使う。
この場合は、上下16%を除いた場合の平均値が得られる。
データが正規分布していると仮定すると、16%とは上下1標準偏差以上・以下のレンジとなっている。
(参考:正規分布)
つまり、外れ値と言ってしまってはやや不正確ではあるが,
データが正規分布していないような凸凹のような分布の場合は、
極値を回避しつつ平均値を求めたいような場合に利用する関数といえる。
平均値と比べて外れ値に強い代表値として中央値(Excelの関数で言えばmedian)が存在するが、
それを使わずに代表値として平均値を利用したいような場合に使う関数といえるのではないだろうか。
- = correl ( 領域1 , 領域2)
-
指定した領域1と領域2の相関係数を計算する。
当たり前だけど、それぞれの領域で同じ数のデータがないと駄目
(一対一対応が成立していないと計算できないということ)。
←疲れているときなどには犯しやすいミスかも。
- = mid (ターゲットのセル番地 , 左から何文字目か , そこから何文字読み取るか)
-
意外なところで役に立つ関数かもしれません。
指定したセルに表示されている文字列の中で、頭文字を取りだしたりするときに使います。
データの区切りがない状態、たとえば、
一つのセルに10桁とか20桁の数字が入っているような場合にも
この関数を使います(SASのデータセットなどで多いのかな?)。
たとえば、D10に収納されている文字列の中で左から3番目の文字だけ取りだしたい
ときには、mid(d10,3,1)といった感じに指定します。
- = count ( 領域 )
-
セル領域の中から、数値データが入力されているセルの個数を調べる。
被験者の人数をカウントするときなどに便利(カモ)。
- = countif ( 領域 , "条件" )
-
選択領域の中から、「”」で括られた条件にマッチするセルの数を調べる。
たとえば、">10"であれば、10よりも大きい数値が入っているセルの数を、"Taira"であれば、Tairaと入力されているセルの数が戻ってくる。頻度表を作るのに必要。
- ピボットテーブル(pivot tables)(詳細はこちらにも書いてあります)
-
頻度などをExcelで一括して扱う場合はピボットテーブル(pivot tables)が簡単で様々な分析できるかもしれません。たとえば、χ2分析をするための元となる表を作成するときにも有用ですし、グラフを作るときにも有用です。
Excelのメニューでは【挿入→ピボットテーブル】で作成できますが、表として分析する領域を選択してから実行すると簡単かもしれません。
たとえば,各列の最後の行に平均値や標準偏差などを求めた結果が含まれていることがあります。ピボットテーブルの機能に平均、標準偏差などを計算する機能が含まれているので、その部分の領域はピボットテーブルとして処理する必要がない領域となります。また、選択する領域全ての列に重複がないユニークな変数名が付けられている必要があります。(最初の一列目が変数名領域として扱われるので、2列続けて変数として表示するような”工夫”は避けるべきです。)
(解説:Create a PivotTable to analyze worksheet data)
- = countblank ( 領域 )
-
空白のセルの数を調べる。欠損値の数を数えるときに便利。
- = max ( 領域 )
-
選択領域の中の最大値を調べる。データの入力ミスの発見に便利。
- = min ( 領域 )
-
選択領域の中の最小値を調べる。データの入力ミスの発見に便利。
- = sumif ( 領域1 , "条件", "領域2" )
-
領域1のセル領域の中で条件にあったもの(行・列)の、
領域2の合計を求める。
たとえば、= sum ( a1:a5 , "Taira" , c1:c5 ) の場合には、
a1〜a5の中でTairaが入力されている行をチェックして、
その行のc列のセルの中の数字を合計する。
集計表の作成に便利。
- = if ( 条件 , 式1 , 式2 )
-
条件にあう場合には、式1を実行し、
条件に合わない場合には式2を実行する。
たとえば、 = if ( A1>10 , "Large", "Small" )とか、
= if ( a1>10 , a1*10 , a1*20 )といった感じ。
- = or ( cond1 , cond2 ) と = and ( cond1 , cond2 )
-
上記のIFと組み合わせると、かなり便利。たとえば、A60に平均値、
A61に標準偏差が記録されていたとする。このとき、= if ( or
( A_i > ( a$60 + a$61*2 ) , A_i < ( a$60 - a$61*2 ) ) ,
"ハズレ値" , "普通の値" )といっ
た具合いにも使える。
ちなみに、データが正規分布している場合には、
平均±1標準偏差の範囲にデータのだいたい70パーセントが含まれる。
また、平均と標準偏差が入力されているセルは、コピー・ペースとしても移動しないように相対指定ではなくて(Y軸に関して)絶対指定にしている。
こうしておくと、この式を横方向にコピー・ペーストしても、中身を修正せずに別の変数の値のグループ化ができるようになる
(列の番号は違っても、同じ行番号に当該変数の平均値と標準偏差が記録されていることを前提としている点に注意されたい)。
- if文のネスト(3つ以上のグループに分ける)※IF文は2016以降3つの引数しか指定できなくなるトラブルが頻発するようになりました。
-
A60に平均値、A61に標準偏差が入っていたとする。このとき、
A1〜A59の範囲のデータを上位15パーセント、中位70パーセント、
下位15パーセントに分けたいときには、if文のネストを行えばよい。
= if ( A_i> ( A$60 + A$61 ) , "Upper" , if ( and ( A_i<( A$60 + A$61
),
A_i > ( A$60 - A$61 ) ) , "Middle" , "Lower" ) )
ちなみに、上記の方法と同じ結果が以下の方法でも導かれる
(こちらの方がエレガントだけど、難しいようだったら、上記の方法で十分でしょう)。
= if ( Ai> ( A$60 + A$61 ) , "Upper" , if (
Ai< ( A$60 - A$61 ) , "Lower" , "Middle" ) )
- IFS関数
-
IF文を使ったネストで条件分岐をする方法を示しましたが、2016以降において導入されたIFS関数はこの条件分岐を直感的に分かりやすくさせる関数です。
=IFS (論理式1, 真の場合1, 論理式2, 真の場合2, …論理式n, 真の場合n)のように指定します。具体的には,
=IFS(K1463>(K$1465+0.5*K$1468),"上位群", K1463>(K$1465 - 0.5*K$1468) , "中位群", K1463<=(K$1465 - 0.5*K$1468 )"下位群") のように指定します。ネスト構造で論理判断するよりもこちらの方が圧倒的に簡単です。
※上記の引数をこのままにして別のセルにコピペしたらどうなるでしょうか?
- その他−おさえておいた方がよい関数
-
校務を念頭におくと、rankやroundが使えるようになっていた方がベターでしょう。
特にS-P表を作るときなどには、rank関数が使えると少し便利になります(データの並べ替えを使った方が楽チンですが…)。
=rank(対象となるセル,データ範囲,オプション)で、そのセルのデータが全体で何位かが求められる。オプションは0か1で、1を指定すると「数値の小さい」順番で番号がつけられ、0だと「数値の大きい」順番で番号がつけられる。
ROUND関数の活用例としては以下のようなものを
挙げることができます。
中間テスト・確認テスト・期末テストの3種類で300点満点であったとき、
その合計得点がセルF3に入っていると仮定します。
以下のようなROUND関数を利用すると10段階の絶対評価が
計算可能になります。
=ROUND(F3/300*10,0)
300点満点なので300点で割って、
それを10倍しROUNDで四捨五入で丸める作業になってます。
たぶん、上記の式でエラーは出ないと思う。しかし、
エラーが出ないということと、
正しい値であるかということとは別の話である。
この辺りの問題はプログラミングの時のバグと全く同じで、
少々泥臭くなっても、
引数にどんな値が入っているかを把握できる程度にネストはとどめた方が無難だと思う。
現在のマーケットのシェア率から考えたら、Excel、ワードといったマイクロソフトのオフィス製品は無視して通りすぎることはできないでしょう。しかし、10年くらい前までは、表計算ソフトはロータス123が最もメジャーなソフトでしたし、ワープロでは一太郎や松といった国産ワープロがメジャーでした。
つまり、もしかしたら、10年後に皆さんが使っているパソコンは、OS(基本ソフト)自体がマイクロソフト以外のものになっているかもしれませんし、オフィススィーツも別の会社のものになっているかもしれないということです。パソコンと付き合うときには、マイクロソフトと一蓮托生になるのはやめた方が無難だと言い換えことができるかもしれません(実際に、学校現場ではまだまだワードよりも一太郎の方がメジャーなソフトですし)。
一応、このことを少し念頭において、Excelやワードを最低限度使いこなせるようになってください。たぶん、関数は全ての表計算ソフトで共通した概念・機能だと思いますので、この辺りの知識はおそらく10年たっても陳腐なものにはならないはずです。
なお、Excelにおける重回帰分析は市販の統計パッケージとは少し異なった特徴があります。
例えばSPSSやStatisticaといった統計パッケージでは、
データの中の欠損値に対して自動的に平均値に補正して計算するような機能が備わってます。
しかし、Excelにおける重回帰分析では、指定した範囲において欠損値
(ゼロととか1ではなく、データそのものが入ってないブランクのセルということ)
が存在すると計算できなくなってしまいます。
これはデータ数が多ければ欠損している部分が存在するケースをそのまま全部削除して対処可能ですが、
データ数が少ない場合には若干躊躇われるかもしれません。
できるだけ欠損値が少なくなるように、要するに、
被験者が答えやすい質問項目を用意する努力が必要と言えるかもしれません。
また複数ある説明変数が飛び飛びに入力している場合には、変数を隣り合う列に入力しておく必要があります。
変数の値を整列するときには単なるコピペでは元の値と変わってしまうことがあるので、
「形式を選択して貼り付け」のメニューの「値だけ」を指定して貼り付けます。
このような手続きを踏まなければならないのもExcel特有の制約かもしれません
(SPSSやStatisticaなど統計専用のソフトの方が圧倒的に楽です)。
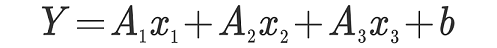

{kind=link}